1.过拟合问题
在机器学习中,有一个问题可能会出现————过拟合问题,在前面我们已经讨论了线性回归问题和Logistic回归问题,我们都是用函数去拟合曲线,那我们评价拟合效果的时候用的是代价函数,那么对于线性回归是不是全部点都满足函数都认为这个拟合效果很好了?对于逻辑回归是不是把所有的数据集都能分类开就很好了?,下面我们来讨论以下这些问题。
线性回归中的过拟合问题:

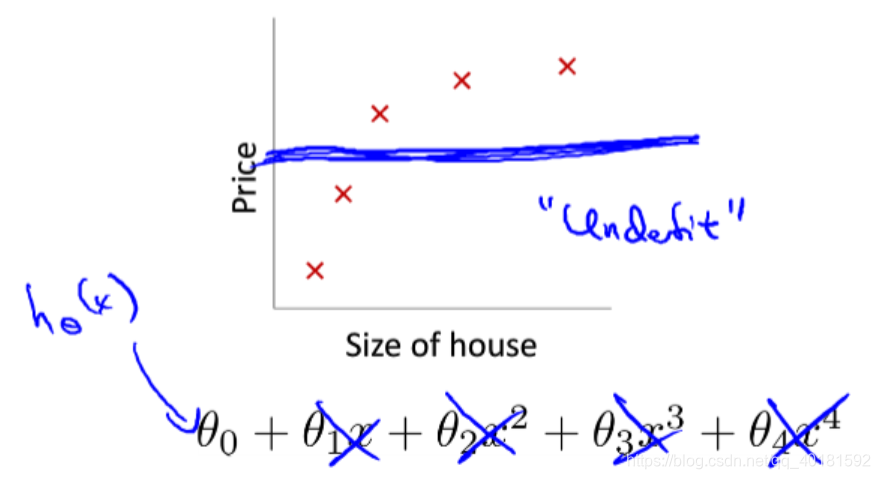
这个例子是我们前面讨论的房价与房子面积大小的问题,对于第一个图来说,我们用一次函数来作为他的假设函数,这样的话得到的代价就比较大,拟合的效果很差,这种情况我们称之为欠拟合(underfit),不能很好的拟合数据集,有很大的偏差,不能做出预测。
第二种情况是用二次函数来拟合,这样的效果比较好,基本符合了数据集的特征,可以作为预测房价的函数。属于正常拟合(just right)。
第三种情况是用许多多项式来拟合,可以发现数据集的所有点都在多项式的曲线上,每个点都符合函数,但是他的图像上下起伏比较大,一会升高一会降低,甚至到后面还是下降,这就不符合我们房价的实际,这种就属于过拟合(overfit),整体走向不对,虽然代价接近于0,但是不是我们想要的假设函数,对于预测数据也不能给出很好的结果。
逻辑回归中的过拟合问题:
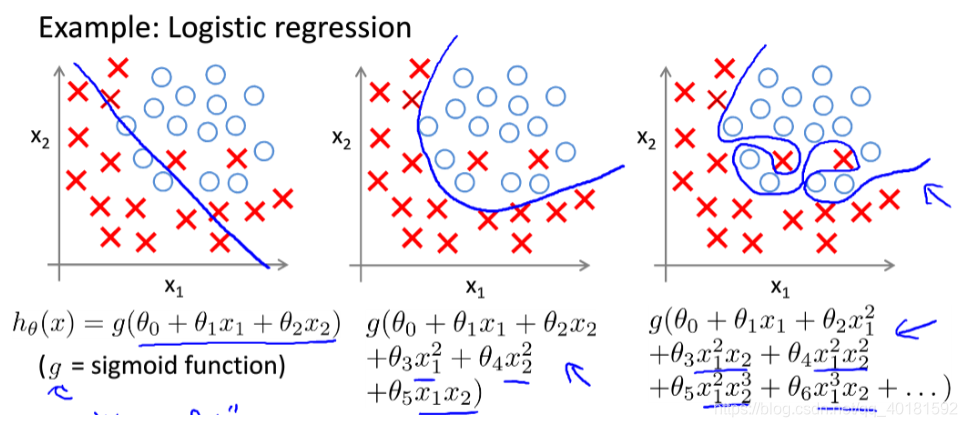
这个例子假设是一个逻辑回归的问题,第一个直接简单的用直线进行划分边界,这样分出的效果是不好的,有一些特征点都分类错了,属于欠拟合。
第二个是用了简单的多项式去拟合,边界平滑,符合要求,是我们想要的结果,可以作为决策边界,属于正常拟合。
第三个和线性回归一样,虽然每个点都被分开了,但是这是刻意得分开,导致边界来回弯曲,不能作为决策边界,假设这是个预测肿瘤恶性、良性的问题,那肯定不能很好的预测,这就是过拟合。
那么我们已经知道了什么是过拟合问题,那么在实际的学习过程中如何避免过拟合问题,如何发现我们是不是做了过拟合呢?
有的人可能会说了看是不是过拟合还不简单,把最后得出的假设函数画出来,看整体的弯曲程度不就行了,这个确实是一个方法,但是有没有想过,当特征变量比较多的时候,假设函数的变量也会增多,图像就不容易画出来,即使画出来了,那个维度我们也很难观察出来是否过拟合,如果只画几个变量,那又要考虑哪些变量不变等等问题,非常麻烦,针对如何看是否出现了过拟合,我们后面会提到,目前相对于这个问题更重要的一个问题是如何避免出现过拟合,这才是我们要讨论的关键。
避免过拟合一般有两个方法:
- 1.人工去除多余的特征变量,出现过拟合问题一般都是特征变量过多,我们可以把一些不重要的特征变量去除,把影响较大的特征变量保留,置于如何判断哪些变量需要保留,哪些需要去除,后面会讲到。
- 2.用正则化的方法,如果很多变量都会对结果产生影响,比如说前面的房价问题,房子的大小,楼层,房间数等都会对房价产生影响,不想去除这些特征变量,那我们就可以使用正则化的方法,保留全部的特征变量,这种我们后面也会讲到。
2.更改代价函数
通过上述的分析我们已经知道了出现过拟合问题的原因就是特征变量过多,下面举一个例子来说明什么是正则化。

这还是之前那个预测房价的问题,第二个多项式拟合是之前的过拟合问题,我们知道出现这个问题其本质还是因为代价函数在作用,才导致选出来的参数0使图像上下浮动很大,所以我们要想解决本质上还得改代价函数,这时我们不妨在原来的代价函数的基础上再加上两项得到:
这里的1000仅代表一个较大的系数,给θ3、θ4大的惩罚,这样对改变过后的代价函数求最小值,求出来的结果是使θ3和θ4都趋近于0,也就是说把后面两项给忽略掉,实际上没有忽略,只是减小他们的值使函数更像是一个二次函数,这样最后得到的图像就如上图品红色线,这就是拟合得到的函数,相比之前的图像起伏不大,并且比二次函数拟合的要好,他还是有趋势的。这就是正则化。
这样我们通过更改代价函数的表达式来有效得避免了过拟合问题,但上述的例子我们是知道θ3和θ4趋近于0,对于其他问题,比如说100个θ的房价预测问题,我们事先不可能知道到底哪些参数要趋近于0,也就不能向上面一样更改代价函数,所以我们如果仍采用正则化的思想,我们就把所有的参数θ都变小,即代价函数变为:
后面的那一项是正则化项,是对所有参数θ的求和乘一个系数,这个系数就是对所有的参数θ的惩罚,使最终的θ都减小,同时这个系数还是权衡拟合效果的比例系数,因为前面是拟合的好坏,后面是起伏的大小,系数的取值不能太大,否则拟合得效果就会很差。还有要提的一点就是求和参数θ的时候没有求θ0,这个没有必要加上因为x0始终是为1的。
假如说正则化项系数取得过大为10的10次方,那么对于预测房价的那个例子,所有的θ都会趋近于0,那么假设函数最终就变成了常数,就是一条水平的直线,这就出现了欠拟合,这显然不能预测房价,拟合效果很差,所以正则化项系数的取值不能过大,后面我们会提到如何选取这个系数。
3.线性回归的正则化
前面我们已经导出带正则化的代价函数,那么下面我们把更改过后的代价函数应用到梯度下降中去,去更改参数θ的更新函数。
这里把θ0和θj分开是因为带正则化的代价函数,只正则化θ1-θj,不包括θ0.
下面是带正则化的更新θ的更新函数,实践上也是对J进行求导得到的:
这样我们就得到了带正则化的梯度下降公式,迭代更新采用这个公式即可。
下面我们再来讨论一下带正则化的正规方程表达式,前面我们也讲到过线性回归可以用正规方程去做,避免了多次迭代,那么带正则化的代价函数的正规方程如下:
这个式子的由来和之前推导正规方程一样求J(0)的偏导数等于0的条件,中间的矩阵除了第一行第一个为0,对角线上的为1,其余的都为0,如果特征变量的个数为n,那么这个矩阵的维度就为(n+1)*(n+1),因为x0全为1,是我们后面加的特征值。
前面我们讲到正规方程的时候还讨论了一下,当特征值较多,数据集较少的时候或者特征值之间有线性关系的时候,这时矩阵容易不可逆,求不出可逆矩阵(如果忘了这一点,可以去翻前面的笔记),但是加入了正则化的正规方程就不会出现矩阵不可逆的情况,这个是有相应的数学证明的,在这里就不再赘述。
4.逻辑回归的正则化
和线性回归一样,我们要想假如正则化,就要改变他的代价函数,我们同样得在逻辑回归原来的代价函数上加上正则项,得到最终的代价函数:
同样的这里的j也是从1-n,那么下面我们就把代价函数求导得到梯度下降的θ的更新表达式,和前面线性回归的一样把θ0单独考虑在外:
再次强调:这里得到的梯度下降的θ的更新表达式和线性回归的表面上一样,但不是同一个算法,因为逻辑回归的假设函数和线性回归的不一样,逻辑回归的假设函数为:
所以两个是不一样的算法,这样我们就把逻辑回归的梯度下降θ的更新表达式求出来了,后面就可以运用这一个了。
前面我们讨论逻辑回归的时候还讲到了高级优化算法,下面我们也把正则化加入到我们的高级优化里面:
高级优化是调用costFunction(theta)函数,所以我们只需要修改这个函数即可:
1
2
3
4
5
6function [jVal,gradient] = costFunction(theta)
jVal = [code to compute J(θ)]; %这里的J(θ)就带正则化的代价函数
gradient(1) = [code to compute J(θ0)'];%这里的J的导数就带上面θ0的导数
gradient(2) = [code to compute J(θ1)'];%这里的导数就带正则化的θ1的导数
···
gradient(n+1) = [code to compute J(θn)];这里也再强调一下,matlab里的下标是从1开始的,而算法中的θ下标是从0开始的,所以最后gradient(n+1)对应的是J(θn).
到目前为止我们已经讨论了线性回归、逻辑回归的梯度下降,线性回归还讨论了特征缩放、正规方程,逻辑回归也讨论了高级优化,可以说我们的机器学习知识已经有了一定得储备,掌握这些方法我们已经能够解决生活中的一些问题,我们需要实践去熟练运用这些算法,后面我们会讨论更复杂的神经网络的知识,最后还是希望大家提出意见,积极指正。